Design in the Age of Transformers: The Architecture That Made GenAI Possible
By Nancy Jain
on
November 25, 2025
Hey Designers, we’re all using GenAI, and many of us are already designing GenAI platforms and AI-agentic experiences every day. but before we race ahead, it’s worth understanding the foundation behind the probabilistic UI and model responses we put in front of users.
Surprisingly, it all traces back to a single idea: the Transformer.
Understanding this foundation will make you a better designer of AI behaviors, guardrails, UX patterns, system affordances, and failure-mode handling.
Just enough to build intuition, confidence, and creative control needed to design for agentic systems.
Let's dive into how Transformers work
To make sense of the Transformer blueprint, we’ll explore text generation step by step.
The first step is tokenization
Models don’t read text the way we do.
" We shine our shoes before leaving home. "
They first break it into tokens i.e. tiny units the system can encode. These tokens are often pieces of words. But in our example, we’ll keep it straightforward and treat every full word as a token.
we | shine | our | shoes | before | leaving | home |
LLMs infer the meaning of a word like “shine” by analyzing its surrounding context in vast training datasets. These datasets consist of billions of words collected from internet text, allowing the model to learn how terms co-occur and relate to one another. (Bolded words below showcase what's providing context)
Street murals shine against faded brickwork.
Their creative ideas shine in team sessions.
Soft lanterns shine through drifting fog.
Her soft laughter shine through quiet rooms.
His polished shoes shine under the studio lights.
Quiet strengths shine under mounting pressure.
The full moon continued to shine over the quiet valley.
Honest intentions shine with genuine warmth.
The snowy rooftops shine under pale moonlight.
Moments of kindness tend to shine when chaos rises.
Eventually, we get a large set of words that frequently appear with ‘shine,’ and another set that rarely or never appear near it in the data.
✅ Words that ARE found alongside "shine" | ❌ Words that ARE NOT found alongside "shine" |
that | taxation |
shoe | neurotransmitter |
again | budget |
metal | cryptography |
bright | algorithmic |
glass | cholesterol |
water | microprocessor |
Next step is Word Embedding
As the model processes this group of words, it builds a long numerical vector i.e. a list of hundreds of values, each reflecting some subtle pattern the model has learned about how a word behaves in real text. This vector is called a word embedding.
For example, [0.42, 0.31, 0.18, 0.57, 0.63, 0.21, 0.49, 0.72, 0.34, 0.28, 0.69, 0.54, 0.39, 0.47, 0.26, 0.61 ….]
It’s similar to describing a painting using many attributes like color palette, texture, lighting, mood — except here the attributes are learned automatically are purely pattern-based.
Because these dimensions aren’t hand-labeled, we can’t say exactly what each value corresponds to.
But we can notice that words used in similar ways tend to end up with embeddings that sit close together in this vector space. For example, forest and woods aren’t perfect substitutes in every sentence, but they often appear in related contexts, so their embeddings land near each other.
forest → [0.58, 0.44, 0.29, 0.62, 0.71, 0.33, 0.41, 0.77, 0.52, 0.38, 0.66 …]
woods → [0.56, 0.42, 0.31, 0.64, 0.73, 0.36, 0.39, 0.74, 0.50, 0.41, 0.68 …]
Likewise, words like whisper and murmur cluster because writers use them in comparable emotional tones.
whisper → [0.61, 0.47, 0.33, 0.72, 0.68, 0.29, 0.55, 0.79, 0.43, 0.52, 0.70 …]
murmur → [0.59, 0.45, 0.35, 0.70, 0.66, 0.31, 0.53, 0.77, 0.45, 0.50, 0.72 …]
And likewise,
taxation → [0.12, 0.83, 0.41, 0.09, 0.77, 0.18, 0.92, 0.34, 0.58, 0.71, 0.15 …]
porcupine → [0.91, 0.14, 0.72, 0.33, 0.28, 0.84, 0.17, 0.59, 0.40, 0.22, 0.93 …]
Just checking if you’re still with me 😄 Yes, since taxation and porcupine are completely unrelated words, their embeddings end up looking very different.
🌟 Fun Fact |
|---|
Today’s frontier models use embeddings anywhere between:
That means one single word is represented by ten thousand numbers describing how that word behaves across billions of sentences. |
Next comes, Self-Attention
Self-attention is the mechanism that allows a Transformer to consider every word in a sentence at the same time and decide which surrounding words matter most.
Transformers have enabled the models to build a full picture of the sentence in a single pass — something earlier approaches like could never do, for example:
RNNs (Recurrent Neural Networks) used to only process text one token after another.
CNNs (Convolutional Neural Networks) used to only look at text in small sliding windows like 2, 3, 5 tokens.
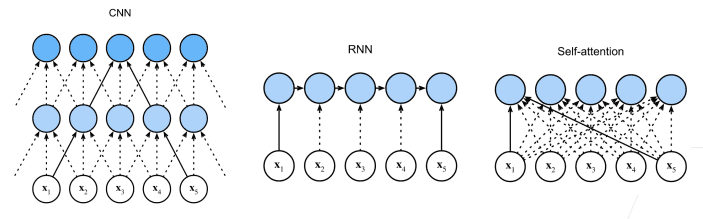
Let's take an example:
“She walked to the bank to deposit her paycheck.”
In this example self-attention highlights deposit, paycheck, and walked to, helping the model understand that bank refers to a financial institution.
Tweaked example:
“They sat on the bank watching the river flow.”
Here, self-attention focuses on river, flow, sat, and watching, making it clear that bank means the land beside a river.
Combining the above examples:
“She deposited her paycheck at the bank before meeting friends on the bank of the river.”
The model understands both meanings by attending to different supporting words:
First bank → deposit, paycheck, bank
Second bank → river, flow, sat, watching
This global view of context is what lets LLMs correctly interpret words with multiple meanings and resolve ambiguities that depend entirely on surrounding text.
Generating Text
After self-attention blends information across all the tokens, the model runs each token through a feed-forward network that refines and transforms its meaning and a few additional normalization steps is repeated many times as the representation becomes more and more context-aware.
Once all those layers have processed the input, the model reaches the final step:
it predicts the next word.
" The designers of this time and age are ________________ "
Pick the most suitable option using probability scores:
facing - 83%
trying - 76%
under - 71%
creators - 67%
However, approach to choose only the single highest-scoring token each time is known as greedy search can lead to awkward phrasing or less relevant completions. Each step might look like a good choice on its own, but the overall sentence may drift off or feel unnatural.
To overcome this, Transformers use more advanced strategies. One of the most common is beam search, which doesn’t just look at the next word in isolation. Instead, it evaluates several possible continuations at once, comparing entire sequences rather than individual tokens.
" The designers of this time and age are ________________ "
pushing the boundaries of creativity
reimagining how we interact with technology
balancing human needs and innovation
shaping systems that feel more human
By exploring multiple pathways before committing, beam search tends to produce more fluent, coherent, and human-like text. It’s not perfect, but it avoids many of the pitfalls of always picking the “locally best” next word.
Closing notes
For years, AI models were built as single-purpose systems, one for translation, another for summarisation, others for search or retrieval. The Transformer changed that by providing one universal blueprint capable of learning many different tasks.
Because the Transformer is a blueprint, many organizations build their models on top of these frameworks:
HuggingFace Transformers → Used across thousands of open-source models (Llama, Falcon, Mistral, BLOOM, T5, etc.)
TensorFlow Transformers (Google) → Used in early Transformer research and models like BERT, T5, and many Google internal systems.
PyTorch Transformer Modules → Backbone for research at OpenAI, Meta, Microsoft, FAIR; used by GPT-2 era and many academic models.
NVIDIA Megatron-LM → Used for training massive models such as GPT-3, Megatron-Turing NLG, and BLOOM-176B.
Microsoft DeepSpeed → Used for GPT-3, OPT-175B, MT-NLG, and large Azure-scale model training.
OpenAI Triton Kernels → Used inside OpenAI models (GPT-4 & GPT-4o family) for custom GPU-level ops and performance tuning.
JAX / Flax Transformers → Used in Google DeepMind research (e.g., PaLM, Gemini components), and high-speed academic research.
Fairseq (Meta) → Used for BART, XLM-R, Wav2Vec, NLLB, and earlier Meta LLMs before LLaMA.
xFormers (Meta) → Used in LLaMA, LLaMA-2, LLaMA-3, and Meta’s optimized attention implementations.
Even when the LLM output feels fluent and coherent, it isn’t guaranteed to be correct. LLMs aren’t search engines, they’re pattern-predictors, choosing the next most likely token. Because of this, they sometimes generate hallucinations: invented facts, dates, quotes, links, or even whole articles.
To improve reliability, humans guide models through RLHF (Reinforcement Learning from Human Feedback) i.e. reviewing responses, correcting errors, and shaping safer behaviour.
Thanks for reading!
——-
Extras
Title options:
The Invisible Revolution Behind GenAI: The Transformer
Design in the Age of Transformers: The Architecture That Made GenAI Possible
The Transformer: The Silent Tool Powering Every AI You Use Today
The Transformer: The Spark Behind the GenAI Universe
First things First (glossary and relationships)
Transformers: Transformers is the architecture that made all GenAI like LLMs, image generators, audio models, multimodal systems possible, made by Google Brain researchers in 2017.
The original Transformer model was detailed in an 11-page publication by eight Google researchers in June 2017, marking a pivotal milestone in generative AI research.
Generative AI: Often shortened to GenAI — is an umbrella term for a broad class of models that can create new content. Not just retrieve, classify, or recommend, but actually generate things: text, images, audio, video, and more.
Landscape of Gen AI models:
LLMs (Large Language Models) → generates text & code
Used for writing text, reasoning, summarization, UX micro-copy, SQL generation, code generation.
Popular examples GPT-4o, Claude 3.5, Gemini 2.0, Llama 3
Diffusion models → generates images
Used for concept art, visual exploration, moodboards, product imagery, iconography.
Popular examples: DALL·E 3, Stable Diffusion XL
Audio Tokens models → generates speech/music
Used for voiceovers, sonic branding, conversational agents, sound design.
Popular examples: AudioLM, VALL-E, ElevenLabs, Suno
Video diffusion models → generates video
Used for concept films, motion design, product video prototypes, storytelling.
Popular examples: Sora, Runway Gen-2, Pika Labs