Behind the Scenes of LLMs: Transformer
By Nancy Jain
on
December 8, 2025
We now use generative AI for speeding up research, brainstorming ideas, polishing presentations, creating mockups, and even producing demo videos. With generative AI powering so much of our work, it is worth understanding how all of this became possible.
Surprisingly, it all traces back to a single idea: the Transformer, introduced by Google Brain researchers in the 2017 paper Attention Is All You Need.
The Transformer is the foundational architecture behind modern generative AI, including large language models (LLMs), image diffusion models, audio models, and multimodal systems.
Understanding this foundation will help us build the intuition and confidence needed to use AI well and to design thoughtful AI experiences for users.
Let us dive into how Transformers work. To make sense of the Transformer blueprint, we will explore LLM text generation flow step by step.
The first step is Tokenization
LLMs don’t read text the way we do. Take this sentence:
" We shine our shoes before leaving home. "
The model first breaks it into tokens, which are tiny units the system can encode. In practice, these tokens are often fractions of words and are not meaningful to humans.
For the sake of simplicity, we will treat each full word as a token and use the terms “token” and “word” interchangeably in this explanation.
we | shine | our | shoes | before | leaving | home |
LLMs infer the meaning of a token like “shine” by analyzing its surrounding context across vast training datasets. These datasets contain billions of words collected from diverse sources on the internet, including forums, books, articles, and many other text repositories. This allows the model to learn how terms co-occur and relate to one another.
The bolded words in below examples show what provides context:
Their creative ideas shine in team sessions.
Soft lanterns shine through drifting fog.
Her soft laughter shine through quiet rooms.
His polished shoes shine under the studio lights.
The full moon continued to shine over the quiet valley.
Honest intentions shine with genuine warmth.
The snowy rooftops shine under pale moonlight.
Eventually, we get a large set of words that frequently appear with ‘shine,’ and another set that rarely or never appear near 'shine' in the data.
✅ Words that ARE found alongside 'shine' | ❌ Words that ARE NOT found alongside 'shine' |
bright | taxation |
shoe | neurotransmitter |
water | budget |
metal | cryptography |
glass | algorithmic |
Next step is Word Embedding
As LLM processes each token, it produces a vector, which is simply a list of values. Each value reflects a subtle pattern the model has learned about how a token behaves in real text. This vector is called a word embedding.
For example, for token "shoe", word embedding would look like: [0.42, 0.31, 0.18, 0.57, 0.63, 0.21, 0.49, 0.72, 0.34, 0.28, 0.69, 0.54, 0.39, 0.47, 0.26, 0.61 …]
It is similar to describing a painting using many attributes like color palette, texture, lighting, and mood. The key difference is that here the attributes are learned automatically and are purely pattern-based. Because these patterns are not hand-labeled, we cannot say exactly what each individual value corresponds to.
But we can notice that tokens used in similar ways tend to end up with embeddings that sit close together in this vector space. For example, silver and gold aren’t perfect substitutes in every sentence, but they often appear in related contexts, so their embeddings land near each other.
silver →
[0.58, 0.44, 0.29, 0.62, 0.71, 0.33, 0.41, 0.77, 0.52, 0.38, 0.66 …]gold →
[0.56, 0.42, 0.31, 0.64, 0.73, 0.36, 0.39, 0.74, 0.50, 0.41, 0.68 …]
Likewise, tokens like talent and potential cluster because writers use them in comparable emotional tones.
talent →
[0.61, 0.47, 0.33, 0.72, 0.68, 0.29, 0.55, 0.79, 0.43, 0.52, 0.70 …]potential →
[0.59, 0.45, 0.35, 0.70, 0.66, 0.31, 0.53, 0.77, 0.45, 0.50, 0.72 …]
And now consider:
taxation →
[0.12, 0.83, 0.41, 0.09, 0.77, 0.18, 0.92, 0.34, 0.58, 0.71, 0.15 …]glass →
[0.91, 0.14, 0.72, 0.33, 0.28, 0.84, 0.17, 0.59, 0.40, 0.22, 0.93 …]
If these two look nothing alike, that is exactly the point. Since taxation and glass are completely unrelated, their embeddings end up very far apart in the vector space.
🤓 Fun Fact |
|---|
Today’s popular LLMs like GPT-4o, Claude 4 Sonnet, and Gemini 2.0 use word embeddings with roughly 4,000 to 10,000 patterns. That means one single token is represented by ten thousand values, each capturing a tiny pattern in how that token behaves across billions of sentences. |
Next comes Self-Attention
Self-attention is the mechanism in a Transformer that allows an LLM to consider every token in a sentence at the same time and decide which surrounding tokens matter most.
Let's take an example:
“She walked to the bank to deposit her paycheck.”
In this example self-attention highlights deposit, paycheck, and walked to, helping the model understand that bank refers to a financial institution.
Tweaked example:
“They sat on the bank watching the river flow.”
Here, self-attention focuses on river, flow, sat, and watching, making it clear that bank means the land beside a river.
Combining the above examples:
“She deposited her paycheck at the bank before meeting friends on the bank of the river.”
The model understands both meanings by attending to different supporting words:
First bank → deposit, paycheck, bank
Second bank → river, flow, sat, watching
This global view of context is what lets LLMs correctly interpret words with multiple meanings and resolve ambiguities that depend entirely on surrounding text.
🤓 Why is Self-Attention a game changer? |
|---|
Self-attention is the part of the Transformer that lets LLMs consider all tokens in a sentence simultaneously and decide which ones matter most to each other. Earlier approaches could not do this. RNNs (Recurrent Neural Networks) processed text one token at a time, and CNNs (Convolutional Neural Networks) viewed text in small fixed-size chunks, often 2, 3, or 5 tokens at a time. 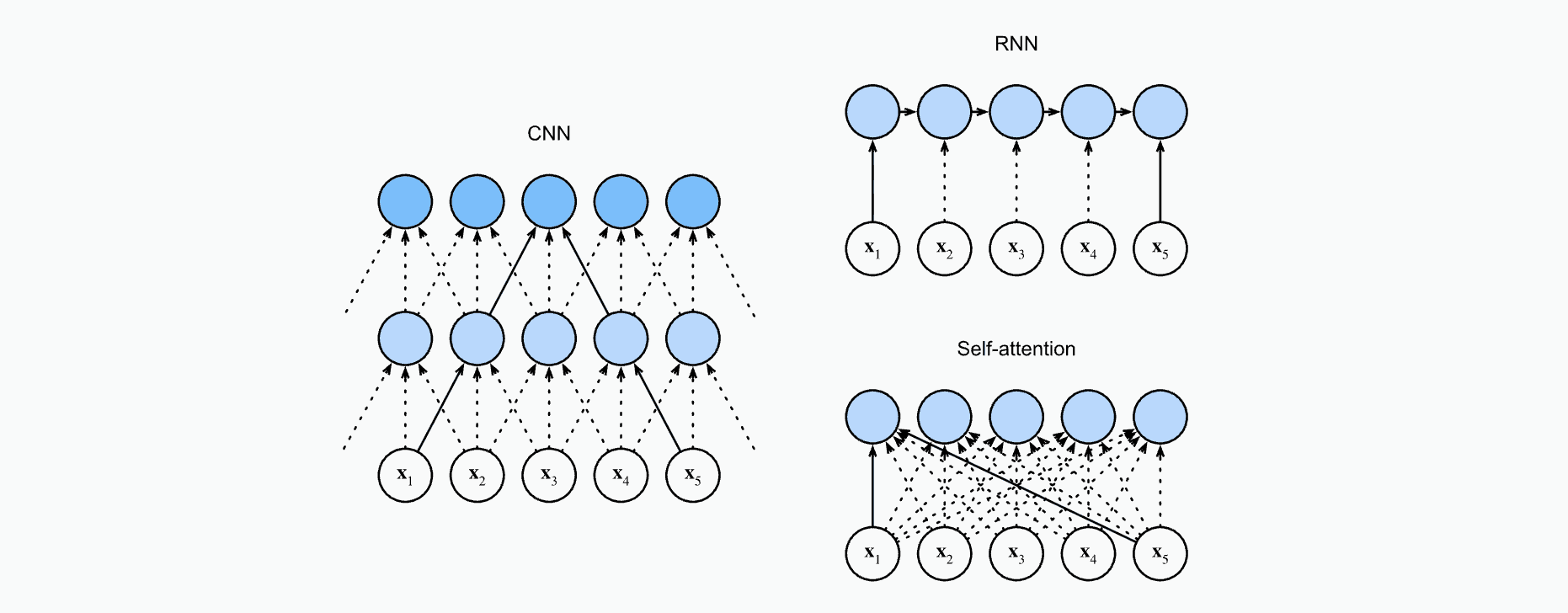 Image credits to d2l.ai |
Final step: Generating Text
After self-attention blends information across all the tokens, the model runs each token through a few more technical steps, then the model reaches the final step: it predicts the next word.
" The designers of this time and age are ________________ "
Pick the most suitable option using probability scores:
facing - 83%
trying - 57%
under - 43%
creators - 22%
However, approach to choose only the single highest-scoring token each time is known as Greedy Search can lead to awkward phrasing or less relevant completions. Each step might look like a good choice on its own, but the overall sentence may drift off or feel unnatural.
To overcome this, Transformers use more advanced strategies. One of the most common is Beam Search, which doesn’t just look at the next word in isolation. Instead, it evaluates several possible continuations at once, comparing entire sequences rather than individual tokens.
" The designers of this time and age are ________________ "
pushing the boundaries of creativity
reimagining how we interact with technology
balancing human needs and innovation
shaping systems that feel more human
By exploring multiple pathways before committing, beam search tends to produce more fluent, coherent, and human-like text. It’s not perfect, but it avoids many of the pitfalls of always picking the “locally best” next word.
For years, AI models were built as single-purpose systems, one for translation, another for summarisation, others for search or retrieval. The Transformer changed that by providing one universal blueprint capable of learning many different tasks.
Thanks for reading!